network socket intro
chapter4
The server must be prepared to accept an incoming connection
connect , accept , and close
Three-Way Handshake
Server - passive open
- socket
- bind
- listen
- accept
Client
- socket
- connect(os will automatic pick one free port to bind) 6. send “synchronize” SYN tells the server the client’s initial sequence number for the data that the client will send on the connection. Normally, there is no data sent with the SYN; it just contains an IP header, a TCP header, and possible TCP options 2.
passive openis the creation of a listening socket, to accept incoming connections. It uses socket(), bind(), listen(), followed by an accept() loop.active openis the creation of a connection to a listening port by a client. It uses socket() and connect().
TCP Connection Termination
close
-
One application calls close first, and we say that this end performs the active close. This end’s TCP sends a FIN segment, which means it is finished sending data.
-
The other end that receives the FIN performs the passive close. The received FIN is acknowledged by TCP. The receipt of the FIN is also passed to the application as an end-of-file (after any data that may have already been queued for the application to receive), since the receipt of the FIN means the application will not receive any additional data on the connection.
-
Sometime later, the application that received the end-of-file will close its socket. This causes its TCP to send a FIN.
-
The TCP on the system that receives this final FIN (the end that did the active close) acknowledges the FIN.
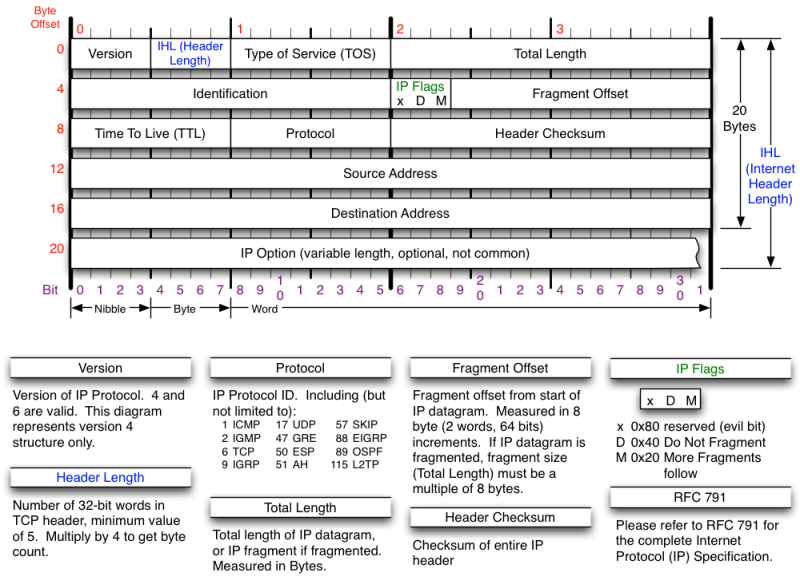
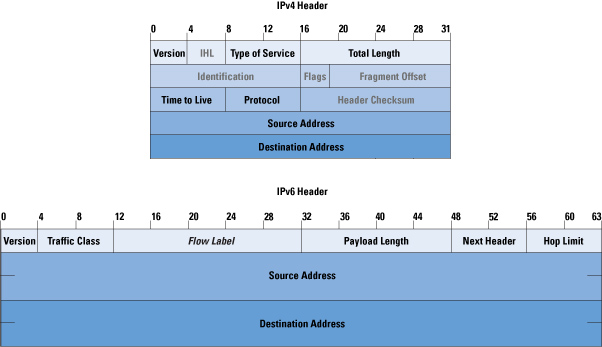
Following are the main differences and comparison between IPv4 header and IPv6 header.
• IPv6 header is much simpler than IPv4 header.
• The size of IPv6 header is much bigger than that of IPv4 header, because of IPv6 address size. IPv4 addresses are 32bit binary numbers and IPv6 addresses are 128 bit binary numbers.
• In IPv4 header, the source and destination IPv4 addresses are 32 bit binary numbers. In IPv6 header, source and destination IPv6 addresses are 128 bit binary numbers.
• IPv4 header includes space for IPv4 options. In IPv6 header, we have a similar feature known as extension header. IPv4 datagram headers are normally 20-byte in length. But we can include IPv4 option values also along with an IPv4 header. In IPv6 header we do not have options, but have extension headers.
• The fields in the IPv4 header such as IHL (Internet Header Length), identification, flags are not present in IPv6 header.
• Time-to-Live (TTL), a field in IPv4 header, typically used for preventing routing loops, is renamed to it’s exact meaning, “Hop Limit”
header size IPV4 16 bytes IPV6 28 bytes
The names of these structures begin with sockaddr_ and end with a unique suffix for each protocol suite
common call “Internet socket address structure”
ipv4 sockaddr_in in <netinet/in.h>
uint8_t in <sys/types.h>
sa_family_t and socklen_t in <sys/socket.h>
in_addr_t in_port_t in <netinet/in.h>
struct in_addr {
in_addr_t s_addr; /* 32-bit IPv4 address */
/* network byte ordered */
};
struct sockaddr_in {
uint8_t sin_len; /*length of structure (16) */
sa_family_t sin_family; /*AF_INET */
in_port_t sin_port; /*16-bit TCP or UDP port number */
/*network byte ordered */
struct in_addr sin_addr; /*32-bit IPv4 address */
/*network byte ordered */
char sin_zero[8]; /*unused */
};
The four socket functions that pass a socket address structure from the process to the kernel
Process2Kernel
bindconnectsendtosendmsg
pass a socket address structure from the process to the kernel. One argument to these three functions is the pointer to the socket address structure and another argument is the integer size of the structure, as in
connect (sockfd, (SA *) &serv, sizeof(serv));
all go through the sockargs function
The five socket functions that pass a socket address structure from the kernel to the process
Kernel2Process
acceptrecvfromrecvmsggetpeernamegetsockname
struct sockaddr_un cli; /* Unix domain */
socklen_t len;
len = sizeof(cli); /* len is a value */
getpeername(unixfd, (SA *) &cli, &len);
/* len may have changed */
all set the sin_len member before returning to the process
The POSIX specification requires only three members in the structure
sin_familysin_addrsin_port
It is acceptable for a POSIX-compliant implementation to define additional structure members, and this is normal for an Internet socket address structure. Almost all implementations add the sin_zero member so that all socket address structures are at least 16 bytes in size.
datatype:
u_charu_shortu_intu_long
Both the IPv4 address and the TCP or UDP port number are always stored in the structure in network byte order
The sin_zero member is unused, but we always set it to 0 when filling in one of these structures. By convention, we always set the entire structure to 0 before filling it in, not just the sin_zero member. Although most uses of the structure do not require that this member be 0, when binding a non-wildcard IPv4 address, this member must be 0 (pp. 731 732 of TCPv2).
Generic Socket Address Structure
A socket address structures is always passed by reference when passed as an argument to any socket functions. But any socket function that takes one of these pointers as an argument must deal with socket address structures from any of the supported protocol families.
struct sockaddr {
uint8_t sa_len;
sa_family_t sa_family; /* address family: AF_xxx value */
char sa_data[14]; /* protocol-specific address */
};
int bind(int, struct sockaddr *, socklen_t);
struct sockaddr_in serv;
/* IPv4 socket address structure */
/* fill in serv{} */
bind(sockfd, (struct sockaddr *) &serv, sizeof(serv));
If we omit the cast ( struct sockaddr * ) the C compiler generates a warning of the form
“warning: passing arg 2 of ‘bind’ from incompatible pointer type,” assuming the system’s
headers have an ANSI C prototype for the bind function.
socklen_t be defined as uint32_t
The IPv6 socket address is defined by including the <netinet/in.h> header
struct in6_addr {
uint8_t s6_addr[16];
/* 128-bit IPv6 address */
/* network byte ordered */
};
#define SIN6_LEN
/* required for compile-time tests */
struct sockaddr_in6 {
uint8_t sin6_len;/*length of this struct (28) */
sa_family_t sin6_family;/*AF_INET6 */
in_port_t sin6_port;/*transport layer port# */
/*network byte ordered */
uint32_t sin6_flowinfo; /*flow information, undefined */
struct in6_addr sin6_addr;/*IPv6 address */
/*network byte ordered */
uint32_t sin6_scope_id; /*set of interfaces for a scope */
};
- The
SIN6_LENconstant must be defined if the system supports the length member for socket address structures. - The IPv6 family is
AF_INET6, whereas theIPv4family isAF_INET. - The
sin6_flowinfomember is divided into two fields:- The low-order 20 bits are the flow label
- The high-order 12 bits are reserved New Generic Socket Address Structure
struct sockaddr_storage include <netinet/in.h>
struct sockaddr_storage {
uint8_t ss_len /* length of this struct (implementation dependent) */
sa_family_t ss_family; /* address family: AF_xxx value */
/* implementation-dependent elements to provide:
* a) alignment sufficient to fulfill the alignment requirements of
*
all socket address types that the system supports.
* b) enough storage to hold any type of socket address that the
*
system supports.
*/
};
two different kind of Byte Ordering address
it depend on Operation System
- low-order
- high-order
The Internet protocols use big-endian byte ordering for these multibyte integers
need to converting between host byte order and network byte order
hmeanhostnmeannetworksmeanshortlmeanlong
#include <netinet/in.h>
/*Both return: value in network byte order*/
uint16_t htons(uint16_t host16bitvalue) ;
uint32_t htonl(uint32_t host32bitvalue) ;
/*Both return: value in host byte order*/
uint16_t ntohs(uint16_t net16bitvalue) ;
uint32_t ntohl(uint32_t net32bitvalue) ;
We should instead think of s as a 16-bit value (such as a TCP or UDP port number) l as a 32-bit value (such as an IPv4 address).
在 UNIX 下面,我們可以改用 stdint.h 這個 header file 中對於資料型態的定義:
改用固定長度的資料型態
int8_t 8-bit signed interger
int16_t 16-bit signed interger
int32_t 32-bit signed interger
int64_t 64-bit signed interger
uint8_t 8-bit unsigned interger
uint16_t 16-bit unsigned interger
uint32_t 32-bit unsigned interger
uint64_t 64-bit unsigned interger
Byte Manipulation Functions
There are two groups of functions that operate on multibyte fields
- Berkeley-derived functions
The first group of functions, whose names begin with b (for byte), are from 4.2BSD and are
still provided by almost any system that supports the socket functions
#include <strings.h>
/*Returns: 0 if equal, nonzero if unequal*/
void bzero(void * dest, size_t nbytes );/*bzero sets the specified number of bytes to 0 in the destination*/
void bcopy(const void * src, void * dest, size_t nbytes );
int bcmp(const void * ptr1, const void * ptr2, size_t nbytes );
-
We often use this function
bzeroto initialize a socket address structure to 0 -
bcopymoves the specified number of bytes from the source to the destination -
bcmpcompares two arbitrary byte strings. The return value is zero if the two byte strings are identical; otherwise, it is nonzero. -
ANSI C
#include <string.h>
/*Returns: 0 if equal, <0 or >0 if unequal (see text)*/
void *memset(void * dest, int c, size_t len );
void *memcpy(void * dest, const void * src, size_t nbytes );
int memcmp(const void * ptr1, const void * ptr2, size_t nbytes );
-
memsetsets the specified number of bytes to the value c in the destination -
memcpyis similar tobcopy,but the order of the two pointer arguments is swapped -
bcopycorrectly handles overlapping fields, while the behavior ofmemcpyis undefined if the source and destination overlap -
The ANSI C
memmovefunction must be used when the fields overlap -
memcmpcompares two arbitrary byte strings and returns 0 if they are identical. If not identical, the return value is either greater than 0 or less than 0, depending on whether the first unequal byte pointed to by ptr1 is greater than or less than the corresponding byte pointed to by ptr2. The comparison is done assuming the two unequal bytes are unsigned chars .
two groups of address conversion functions
#include <arpa/inet.h>
//Returns: 1 if string was valid, 0 on error
int inet_aton(const char * strptr, struct in_addr * addrptr );
//Returns: 32-bit binary network byte ordered IPv4 address; INADDR_NONE if error
in_addr_t inet_addr(const char * strptr );
//Returns: pointer to dotted-decimal string
char *inet_ntoa(struct in_addr inaddr );
convert Internet addresses between ASCII strings (what humans prefer to use) and network byte ordered binary values (values that are stored in socket address structures)
inet_aton,inet_ntoa, andinet_addrconvert an IPv4 address from a dotted-decimal string (e.g.,206.168.112.96) to its 32-bit network byte ordered binary value. You will probably encounter these functions in lots of existing code.- The newer functions,
inet_ptonandinet_ntop, handle bothIPv4andIPv6addresses. We describe these two functions in the next section and use them throughout the text.
inet_atonconverts the C character string pointed to by strptr into its 32-bit binary network byte ordered value, which is stored through the pointer addrptr. If successful, 1 is returned; otherwise, 0 is returnedinet_ntoadeprecated, not use it anymoreThe inet_ntoafunction converts a 32-bit binary network byte ordered IPv4 address into its corresponding dotted-decimal string. The string pointed to by the return value of the function resides in static memory.
Functions that take actual structures as arguments are rare. It is more common to pass a pointer to the structure.
inet_pton and inet_ntop Functions two functions are new with IPv6 and work with both IPv4 and IPv6 addresses
p mean presentation The presentation format for an address is often an ASCII string
n mean numeric the numeric format is the binary value that goes into a socket address structure
#include <arpa/inet.h>
//Returns: 1 if OK, 0 if input not a valid presentation format, -1 on error
int inet_pton(int family, const char * strptr, void * addrptr );
//Returns: pointer to result if OK, NULL on error
const char *inet_ntop(int family, const void * addrptr, char * strptr, size_t len );
- the
familyargument for both functions is eitherAF_INETorAF_INET6, If family is not supported, both functions return an error with errno set toEAFNOSUPPORT inet_ptontries to convert the string pointed to by strptr, storing the binary result through the pointer addrptr. If successful, the return value is 1. If the input string is not a valid presentation format for the specified family, 0 is returned.inet_ntopdoes the reverse conversion, from numeric (addrptr) to presentation (strptr). The len argument is the size of the destination, to prevent the function from overflowing the caller’s buffer.
To help specify this size the following two definitions are defined by including the <netinet/in.h> header
#define INET_ADDRSTRLEN 16 /* for IPv4 dotted-decimal */
#define INET6_ADDRSTRLEN 46 /* for IPv6 hex string */
If len is too small to hold the resulting presentation format, including the terminating null, a null pointer is returned and errno is set to ENOSPC .

//ipv4
// to numberic
foo.sin_addr.s_addr = inet_addr(cp);
// n to p
ptr = inet_ntoa(foo.sin_addr);
replace with
inet_pton(AF_INET, cp, &foo.sin_addr);
char str[INET_ADDRSTRLEN];
ptr = inet_ntop(AF_INET, &foo.sin_addr, str, sizeof(str));
Simple version of inet_pton that supports only IPv4.
int inet_pton(int family, const char *strptr, void *addrptr){
if (family == AF_INET) {
struct in_addr in_val;
if (inet_aton(strptr, &in_val)) {
memcpy(addrptr, &in_val, sizeof(struct in_addr));
return (1);
}
return (0);
}
errno = EAFNOSUPPORT;
return (-1);
}
Simple version of inet_ntop that supports only IPv4
const char *
inet_ntop(int family, const void *addrptr, char *strptr, size_t len)
{
const u_char *p = (const u_char *) addrptr;
if (family == AF_INET) {
char temp[INET_ADDRSTRLEN];
snprintf(temp, sizeof(temp), "%d.%d.%d.%d",
p[0], p[1], p[2], p[3]);
if (strlen(temp) >= len) {
errno = ENOSPC;
return (NULL);
}
strcpy(strptr, temp);
return (strptr);
}
errno = EAFNOSUPPORT;
return (NULL);
}
readn , writen , and readline Functions
{% include_code unix_network_programming/lib/readn.c [lang:c] readn%}
{% include_code unix_network_programming/lib/writen.c [lang:c] writen %}
{% include_code unix_network_programming/test/readline1.c cpp [lang:c] readline1 %}
Better version of readline function
{% include_code unix_network_programming/lib/readline.c [lang:c] readline %}
SYN option
-
MSS option(maximum segment size)
TCP_MAXSEG
-
Window scale option
SO_RCVBUF
-
Timestamp option
no need to worry
maximum segment lifetime (MSL), sometimes called 2MSL.
Maximum Transmission Unit,縮寫MTU
-
getaddrinfo using name to get addr
-
getnameinfo using addr to get name
-
getsockname return the protocol address server calls getsockname to obtain the destination IP address from the client
-
inet_ntop convert the 32-bit IP address in the socket address structure to a dotted-decimal ASCII string
-
ntohs convert the 16-bit port number from network byte order to host byte order
note:
normally avoid bind port less than 1024
bind error: Permission denied
<netinet/in.h>
contain INADDR_
socket
To perform network I/O, the first thing a process must do is call the socket function, specifying the type of communication protocol desired (TCP using IPv4, UDP using IPv6, Unix domain stream protocol, etc.)
socket types
| Type | Description |
|---|---|
| SOCK_STREAM | stream socket |
| SOCK_DGRAM | datagram socket |
| SOCK_SEQPACKET | sequenced packet socket |
| SOCK_RAW | raw socket |
protocol
| Protocl | Description |
|---|---|
| IPPROTO_TCP | TCP transport protocol |
| IPPROTO_UDP | UDDP transport protocol |
| IPPROTO_SCTP | SCTP transport protocol |
#include <sys/socket.h>
int socket (int family, int type, int protocol ) ;
#Returns: non-negative descriptor if OK, -1 on error
connect
The connect function is used by a TCP client to establish a connection with a TCP server.
#include <sys/socket.h>
int connect(int sockfd, const struct sockaddr * servaddr, socklen_t addrlen ) ;
#Returns: 0 if OK, -1 on error
error scenario
ETIMEDOUT
send SYN, the respond time out
If the client TCP receives no response to its SYN segment, ETIMEDOUT is returned.
4.4BSD, for example, sends one SYN when connect is called, another 6 seconds
later, and another 24 seconds later (p. 828 of TCPv2). If no response is received
after a total of 75 seconds, the error is returned.
Some systems provide administrative control over this timeout; see Appendix E of
TCPv1.
ECONNREFUSED
If the server’s response to the client’s SYN is a reset (RST), this indicates that no process is waiting for connections on the server host at the port specified
`RST` in 3 condition
An RST is a type of TCP segment that is sent by TCP when something is wrong
1. when a `SYN` arrives for a port that has no listening server
2. when TCP wants to abort an existing connection
3. when TCP receives a segment for a connection that does not exist
EHOSTUNREACHorENETUNREACH
If the client’s SYN elicits an ICMP “destination unreachable” from some intermediate
router, this is considered a soft error. The client kernel saves the message but keeps
sending SYNs with the same time between each SYN as in the first scenario. If no
response is received after some fixed amount of time (75 seconds for 4.4BSD), the
saved ICMP error is returned to the process as either EHOSTUNREACH or ENETUNREACH .
It is also possible that the remote system is not reachable by any route in the local system’s forwarding table, or that the connect call returns without waiting at all.
Common scenario
solaris % daytimetcpcli 127.0.0.1
Sun Jul 27 22:01:51 2003
//connect to daytime server
solaris % daytimetcpcli 192.6.38.100
Sun Jul 27 22:04:59 PDT 2003
// connect to local subnet 192.168.1/24, but 100 is not exist
// err_sys say ETIMEDOUT error
solaris % daytimetcpcli 192.168.1.100
connect error: Connection timed out
// connect a host not running daytime service
solaris % daytimetcpcli 192.168.1.5
connect error: Connection refused
//IP address that is not reachable on the Internet
// err_sys say ETIMEDOUT, connect returns the EHOSTUNREACH error
// only after waiting its specified amount of time
solaris % daytimetcpcli 192.3.4.5
connect error: No route to host
### bind
The `bind` function assigns a local protocol address to a socket. With the Internet protocols,
the protocol address is the combination of either a `32-bit IPv4 address` or a `128-bit IPv6
address`, along with a `16-bit TCP or UDP port number`.
```c
#include <sys/socket.h>
int bind (int sockfd, const struct sockaddr * myaddr, socklen_t addrlen );
//Returns: 0 if OK,-1 on error
bind assigns a protocol address to a socket, and what that protocol address
means depends on the protoco
The second argument is a pointer to a protocol-specific address, and the third argument is the size of this address structure. With TCP, calling bind lets us specify a port number, an IP address, both, or neither.
-
Servers bind their well-known port when they start, or no setup, the kernel chooses an ephemeral port for the socket when either connect or listen is called
- server side will pick well-know port, except Remote Procedure Call (RPC) servers, They normally let the kernel choose an ephemeral port for their listening socket since this port is then registered with the RPC port mapper. Clients have to contact the port mapper to obtain the ephemeral port before they can connect to the server. This also applies to RPC servers using UDP
- client use ephemeral port
-
A process can bind a
specific IP addressto itssocket. The IP address must belong to an interface on the host
- client, this assigns the source IP address that will be used for IP datagrams sent on the socket client does not bind an IP address to its socket. The kernel chooses the source IP address when the socket is connected, based on the outgoing interface that is used
- server, this restricts the socket to receive incoming client connections destined only to that IP address If a TCP server does not bind an IP address to its socket, the kernel uses the destination IP address of the client’s SYN as the server’s source IP address
sin_addr, sin_port
sin6_addr, sin6_port
If we specify a port number of 0, the kernel chooses an ephemeral port when bind is called. But if we specify a wildcard IP address, the kernel does not choose the local IP address until either the socket is connected (TCP) or a datagram is sent on the socket (UDP).
With IPv4, the wildcard address is specified by the constant INADDR_ANY , whose value is
normally 0. This tells the kernel to choose the IP address
struct sockaddr_i servaddr;
servaddr.sin_addr.s_addr = htonl (INADDR_ANY); /* wildcard */
struct sockaddr_in6 serv;
serv.sin6_addr = in6addr_any; /* wildcard */
The system allocates and initializes the in6addr_any variable to the constant
IN6ADDR_ANY_INIT . The <netinet/in.h> header contains the extern declaration for
in6addr_any .
The value of INADDR_ANY (0) is the same in either network or host byte order, so the use of
htonl is not really required. But, since all the INADDR _constants defined by the
<netinet/in.h> header are defined in host byte order, we should use htonl with any of
these constants.
Common errror
EADDRINUSE (“Address already in use”)
use SO_REUSEADDR and SO_REUSEPORT socket options
listen
The listen function is called only by a TCP server and it performs two actions
-
When a socket is created by the socket function, it is assumed to be an active socket, that is, a client socket that will issue a connect . The listen function converts an unconnected socket into a passive socket, indicating that the kernel should accept incoming connection requests directed to this socket.
the call to listen moves the socket from the
CLOSEDstate to theLISTENstate. -
The second argument to this function specifies the maximum number of connections the kernel should queue for this socket
#include <sys/socket.h>
#int listen (int sockfd, int backlog );
//Returns: 0 if OK, -1 on error
This function is normally called after both the socket and bind functions and must be
called before calling the accept function.
backlog has two queues
-
incomplete connection queue
which contains an entry for each SYN that has arrived from a client for which the server is awaiting completion of the TCP three-way handshake. These sockets are in the SYN_RCVD state
-
completed connection queue
which contains an entry for each client with whom the TCP three-way handshake has completed. These sockets are in the ESTABLISHED state
-
client sent SYN(C),
entry incomplete queue -
server sent ACK(C+1) + SYN(S) to client
-
client sent ACK(S+1) to server, compelete 3 hand shake,
entry complete queue -
accept, get from compelete queueWhen the process calls
accept, which we will describe in the next section, the first entry on the completed queue is returned to the process, or if the queue is empty, the process is put to sleep until an entry is placed onto the completed queue
if This entry will remain on the incomplete queue until the third segment of the three-way handshake arrives, or timeout
time between 2 to 3 call RTT round trip time
About two queues
- The
backlogargument to thelistenfunction has historically specified the maximum value for the sum of both queues. - Berkeley-derived implementations add a fudge factor to the backlog: It is multiplied by
1.5 - Do not specify a backlog of 0
- Many current systems allow the administrator to modify the maximum value for the backlog
- A problem is: What value should the application specify for the backlog using dynamic value from command args, or enviorment variable
{% include_code unix_network_programming/lib/wrapsock.c [lang:c] %}
-
the reason for queuing a fixed number of connections is to handle the case of the server process being busy between successive calls to
acceptincompelete queue larger than compelete queue, the reason for specifying a large backlog is because the incomplete connection queue can grow as client SYNs arrive, waiting for completion of the three-way handshake. -
TCP ignores the arriving SYN, when queues are full
Some implementations do send an RST when the queue is full. This behavior is incorrect for the reasons stated above, and unless your client specifically needs to interact with such a server, it’s best to ignore this possibility. Coding to handle this case reduces the robustness of the client and puts more load on the network in the normal RST case, where the port really has no server listening on it
-
Data that arrives after the three-way handshake completes, but before the server calls accept , should be queued by the server TCP, up to the size of the connected socket’s receive buffer.
accept
accept is called by a TCP server to return the next completed connection from the front of
the completed connection queue, If the completed connection queue is empty,
the process is put to sleep
#include <sys/socket.h>
int accept (int sockfd, struct sockaddr * cliaddr, socklen_t * addrlen ) ;
// Returns: non-negative descriptor if OK, -1 on error
- listening socket (the descriptor created by socket and then used as the first argument to both bind and listen )
- cliaddr return the protocol address of the connected peer process(client)
- addrlen is a value-result argument
If accept is successful, its return value is a brand-new descriptor automatically created by the kernel
return
- an integer return code that is either a new socket descriptor or an error indication
- the protocol address of the client process (through the cliaddr pointer)
- the size of this address (through the addrlen pointer)
If we are not interested in having the protocol address of the client returned, we set both cliaddr and addrlen to null pointers.
see example
{% include_code unix_network_programming/intro/daytimetcpsrv1.c [lang:c] %}
fork and exec
#include <unistd.h>
pid_t fork(void);
// Returns: 0 in child, process ID of child in parent, -1 on error
call fork from parent, return two
- to parent, return process ID of the newly created process (the child)
- to child, with a return value of 0
that can tell which is parenet, which is child
Child
The reason fork returns 0 in the child, instead of the parent’s process ID, is because a
child has only one parent and it can always obtain the parent’s process ID by calling
getppid
Parent
A parent, on the other hand, can have any number of children, and there is no way to obtain the process IDs of its children. If a parent wants to keep track of the process IDs of all its children, it must record the return values from fork .
There are two typical uses of fork :
-
A process makes a copy of itself so that one copy can handle one operation while the other copy does another task. This is typical for network servers. We will see many examples of this later in the text.
-
A process wants to execute another program. Since the only way to create a new process is by calling fork , the process first calls fork to make a copy of itself, and then one of the copies (typically the child process) calls exec (described next) to replace itself with the new program. This is typical for programs such as shells.
the six exec function
#include <unistd.h>
int execl (const char * pathname, const char *arg0, ... /* (char *) 0 */ );
int execv (const char * pathname, char *const argv []);
int execle (const char * pathname, const char * arg 0, ...
/* (char *) 0, char *const envp [] */ );
int execve (const char * pathname, char *const argv [], char *const envp []);
int execlp (const char * filename, const char * arg 0, ... /* (char *) 0 */ );
int execvp (const char * filename, char *const argv []);
// All six return: -1 on error, no return on success
These functions return to the caller only if an error occurs. Otherwise, control passes to the start of the new program, normally the main function.
Normally, only execve
is a system call within the kernel and the other five are library functions that call execve .
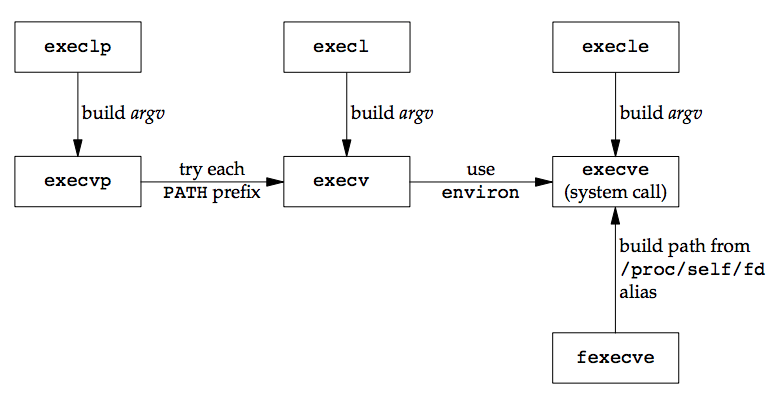
Note the following differences among these six functions:
- The three functions in the top row specify each argument string as a separate argument to the exec function, with a null pointer terminating the variable number of arguments. The three functions in the second row have an argv array, containing pointers to the argument strings. This argv array must contain a null pointer to specify its end, since a count is not specified.
- The two functions in the left column specify a filename argument. This is converted into a pathname using the current PATH environment variable. If the filename argument to execlp or execvp contains a slash (/) anywhere in the string, the PATH variable is not used. The four functions in the right two columns specify a fully qualified pathname argument.
- The four functions in the left two columns do not specify an explicit environment pointer. Instead, the current value of the external variable environ is used for building an environment list that is passed to the new program. The two functions in the right column specify an explicit environment list. The envp array of pointers must be terminated by a null pointer. Descriptors open in the process before calling exec normally remain open across the exec . We use the qualifier “normally” because this can be disabled using fcntl to set the FD_CLOEXEC descriptor flag. The inetd server uses this feature
Concurrent Servers
pid_t pid;
int listenfd, connfd;
listenfd = Socket( ... );
/* fill in sockaddr_in{} with server's well-known port */
Bind(listenfd, ... );
Listen(listenfd, LISTENQ);
for ( ; ; ) {
connfd = Accept (listenfd, ... );
/* probably blocks */
if( (pid = Fork()) == 0) {
Close(listenfd);
/* child closes listening socket */
doit(connfd);
/* process the request */
Close(connfd);
/* done with this client */
exit(0);
/* child terminates */
}
Close(connfd);
/* parent closes connected socket */
}
close will issue the FIN
- server send FIN(S) - server active close, client close wait(passive close)
- client send ACK(S+1) - server FIN_WAIT_2,
- client send FIN(C) - client LAST_ACK, close
- server send ACK(C+1) - server Time_WAIT, client close
that’s visulize whole process of fork
- the status of the client and server while the server is blocked in the call to accept and the connection request arrives from the client

- The connection is accepted by the kernel and a new socket, connfd , is created. This is a connected socket and data can now be read and written across the connection.

- The next step in the concurrent server is to call fork
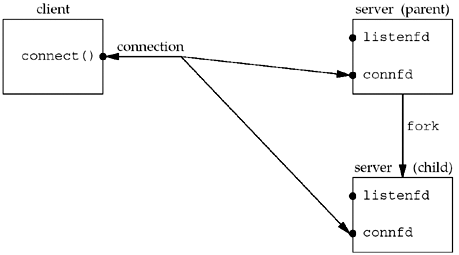
Notice that both descriptors, listenfd and connfd , are shared (duplicated) between the parent and child.
- the parent to close the connected socket and the child to close the listening socket
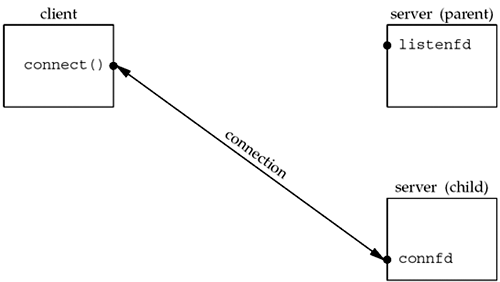
This is the desired final state of the sockets. The child is handling the connection with the client and the parent can call accept again on the listening socket, to handle the next client connection.
close
The normal Unix close function is also used to close a socket and terminate a TCP connection.
#include <unistd.h>
int close (int sockfd );
//Returns: 0 if OK, -1 on error
The default action of close with a TCP socket is to mark the socket as closed and return to the process immediately
The socket descriptor is no longer usable by the process: It cannot be used as an argument to read or write . But, TCP will try to send any data that is already queued to be sent to the other end, and after this occurs, the normal TCP connection termination sequence takes place
Note:
if reference count was still greater than 0, the close do not initiate TCP`s four packet connection termination sequence
close action
- decrese reference count
- if reference count
less or equal to 0, initiate termination
fork action
- increase refernce count on same file description
We must also be aware of what happens in our concurrent server if the parent does not call close for each connected socket returned by accept . First, the parent will eventually run out of descriptors, as there is usually a limit to the number of descriptors that any process can have open at any time. But more importantly, none of the client connections will be terminated. When the child closes the connected socket, its reference count will go from 2 to 1 and it will remain at 1 since the parent never closes the connected socket. This will prevent TCP’s connection termination sequence from occurring, and the connection will remain open.
shutdown
If we really want to send a FIN on a TCP connection, the shutdown function can be used instead of close .
getsockname and getpeername
These two functions return either the local protocol address associated with a socket ( getsockname ) or the foreign protocol address associated with a socket ( getpeername ).
#include <sys/socket.h>
int getsockname(int sockfd, struct sockaddr * localaddr, socklen_t * addrlen );
int getpeername(int sockfd, struct sockaddr * peeraddr, socklen_t * addrlen );
//Both return: 0 if OK, -1 on error
Notice that the final argument for both functions is a value-result argument. That is, both
functions fill in the socket address structure pointed to by localaddr or peeraddr.
Why need these
-
After connect successfully returns in a TCP client that does not call bind , getsockname returns the local IP address and local port number assigned to the connection by the kernel.
-
After calling bind with a port number of 0 (telling the kernel to choose the local port number), getsockname returns the local port number that was assigned.
-
getsockname can be called to obtain the address family of a socket
-
In a TCP server that binds the wildcard IP address, once a connection is established with a client ( accept returns successfully), the server can call getsockname to obtain the local IP address assigned to the connection. The socket descriptor argument in this call must be that of the connected socket, and not the listening socket.
-
When a server is
execed by the process that callsaccept, the only way the server can obtain the identity of the client is to callgetpeername.
{% include_code unix_network_programming/lib/sockfd_to_family.c [lang:c] %}
Allocate room for largest socket address structure
Since we do not know what type of socket address structure to allocate, we use a sockaddr_storage value, since it can hold any socket address structure supported by the system
Since the POSIX specification allows a call to getsockname on an unbound socket, this function should work for any open socket descriptor TCP/IP State Transition Diagram
capable with ipv4 and v6
sock_ntop and Related Functions
the shortcome of inet_ntop is we must know the the format of the structure and the address family , like ipv4 or ipv6, and each one is protocal depend,
This makes our code protocol-dependent.
ipv4
struct sockaddr_in addr;
inet_ntop(AF_INET, &addr.sin_addr, str, sizeof(str));
ipv6
struct sockaddr_in6 addr6;
inet_ntop(AF_INET6, &addr6.sin6_addr, str, sizeof(str));
char *
sock_ntop(const struct sockaddr *sa, socklen_t salen)
{
char portstr[8];
static char str[128]; /* Unix domain is largest */
switch (sa->sa_family) {
case AF_INET: {
struct sockaddr_in *sin = (struct sockaddr_in *) sa;
if (inet_ntop(AF_INET, &sin->sin_addr, str, sizeof(str)) == NULL)
return(NULL);
if (ntohs(sin->sin_port) != 0) {
snprintf(portstr, sizeof(portstr), ":%d", ntohs(sin->sin_port));
strcat(str, portstr);
}
return(str);
}
/* end sock_ntop */
#ifdef IPV6
case AF_INET6: {
struct sockaddr_in6 *sin6 = (struct sockaddr_in6 *) sa;
str[0] = '[';
if (inet_ntop(AF_INET6, &sin6->sin6_addr, str + 1, sizeof(str) - 1) == NULL)
return(NULL);
if (ntohs(sin6->sin6_port) != 0) {
snprintf(portstr, sizeof(portstr), "]:%d", ntohs(sin6->sin6_port));
strcat(str, portstr);
return(str);
}
return (str + 1);
}
#endif
#ifdef AF_UNIX
case AF_UNIX: {
struct sockaddr_un *unp = (struct sockaddr_un *) sa;
/* OK to have no pathname bound to the socket: happens on
every connect() unless client calls bind() first. */
if (unp->sun_path[0] == 0)
strcpy(str, "(no pathname bound)");
else
snprintf(str, sizeof(str), "%s", unp->sun_path);
return(str);
}
#endif
#ifdef HAVE_SOCKADDR_DL_STRUCT
case AF_LINK: {
struct sockaddr_dl *sdl = (struct sockaddr_dl *) sa;
if (sdl->sdl_nlen > 0)
snprintf(str, sizeof(str), "%*s (index %d)",
sdl->sdl_nlen, &sdl->sdl_data[0], sdl->sdl_index);
else
snprintf(str, sizeof(str), "AF_LINK, index=%d", sdl->sdl_index);
return(str);
}
#endif
default:
snprintf(str, sizeof(str), "sock_ntop: unknown AF_xxx: %d, len %d",
sa->sa_family, salen);
return(str);
}
return (NULL);
}
RTT 同一個封包來回時間(Round-Trip Time)
RST Reset a connection
wait adn waitpid
#include <sys/wait.h>
pid_t wait ( int *statloc);
pid_t waitpid ( pid_t pid, int *statloc, int options);
// Both return: process ID if OK, 0 or 1 on error
- child terminated normally
- killed by a signal
- stopped by job control
If there are no terminated children for the process calling wait , but the process has one or
more children that are still executing, then wait blocks until the first of the existing
children terminates.
parent call wait, parent wait block, until child(or one of them) exit
waitpid gives us more control over which process to wait for and whether or not to block
pid = -1wait for the first of our children to terminateWNOHANGThis option tells the kernel not to block if there are no terminated children
Common command
netstat
-
List all listening ports:
netstat -l -
List listening TCP ports:
netstat -t -
Display PID and program names:
netstat -p -
List information continuously:
netstat -c -
List routes and do not resolve IP to hostname:
netstat -rn ```
- List listening TCP and UDP ports (+ user and process if you're root):
```
netstat -lepunt